I love this diagram. Source.
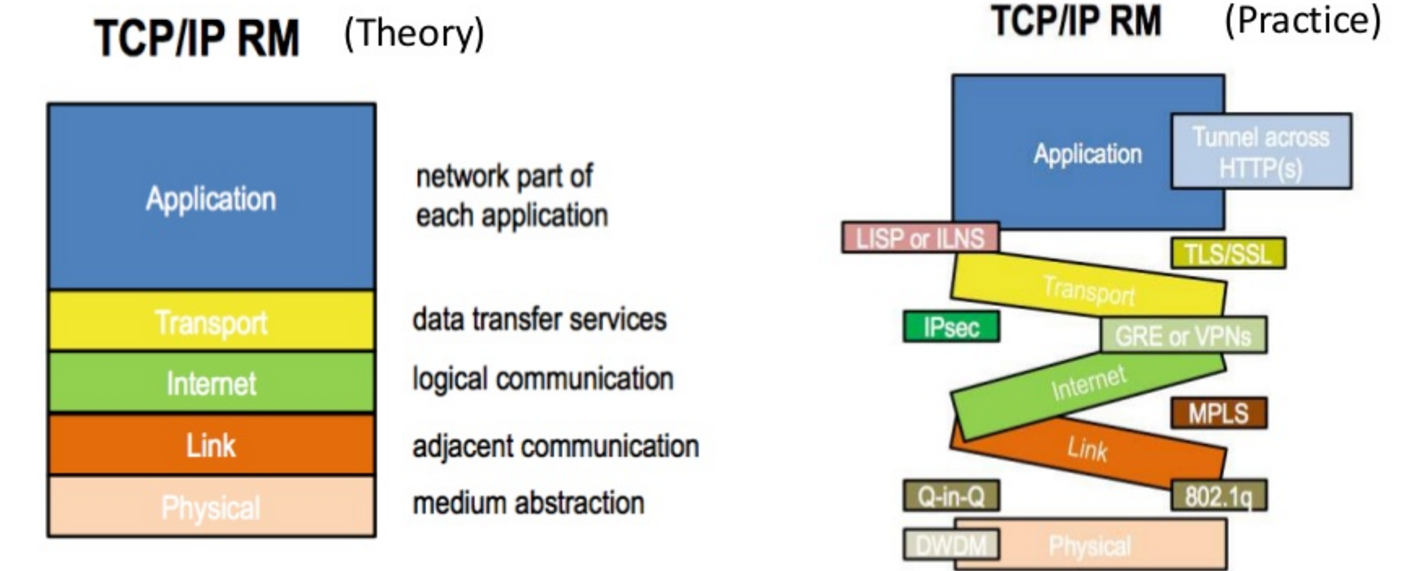
I love this diagram. Source.
If you into networking or specifically P4 you should take a look at the recent P4 workshop presentations.
A while ago the Packet Pushers had Geoff Huston on as a guest in the future of networking series. There are lots of good ideas and contrarian opinions in that podcast episode – go listen to it.
During the episode, Geoff mentioned a book that had a big influence on him called An Engineering Approach to Computer Networking. Naturally, I ordered a copy.
The first thing you’ll notice reading this book is that some aspects are dated – it was written in 1996 after all. This becomes obvious early on when ATM is mentioned as the likely replacement for Ethernet and how it will play a major role in the future – obviously that didn’t work out.
Fortunately, most of the content is much more timeless.
Almost all networking books that try to be computer science or engineering text books are much closer to being descriptions of how IP networking works vs. really teaching the science behind networking. This book is the opposite – it’s not the book to read if you want to win an IP networking quiz show.
The principles discussed throughout the book underlie all circuit and packet switched networks so digging into details that may seem out of date is still well worth the time. This helps to build a solid foundation and gives a bit of perspective on how and why so much has stayed the same.
I’m not going to bother giving this book any kind of rating. If you have an interest in computer networking you should read it. For an even more abstract and science based view of computer networking you should also read my favourite networking book – Patterns in Networking Architecture.
I recently finished reading The Art of Network Architecture. If I remember correctly, I found out about this book during an episode of the Packet Pushers where the author participated.
I ordered the book based on the promise of discussion of SDN use cases and SDN networking in general. It turns out that this wasn’t the best book to dig into that area but it does offer a nice overview and reminder of networking concepts across all areas of networking from design to management. So while parts are a bit fluffy and common sense, it was worth reading in the same way a good survey paper is.
I’ve done a bit of research into P4 recently. Figuring out if the IP-[TCP/UDP] mono-culture is here stay is a long-term interest of mine and P4 is perhaps one way to break that mono-culture.
One of the use cases presented for P4 is in-band telemetry. None of this really requires P4 but it’s interesting to think about hardware driven implementations.
Part 1: Internet Redundancy, Or Not
Part 2: Redundant Connections to a Single Host?
In the last post I discussed how devices like your laptop and mobile phone are computing devices with multiple Internet connections not all that different from a network with multiple connections. The anecdote about Skype on a mobile phone reconnecting a call after you leave the range of Wi-Fi alludes to one key difference. That is, a device directly connected to a particular network connection can easily detect a total failure of said connection. In the example, this allowed Skype to quickly try to reconnect using the phone’s cellular connection.
Think back to our initial problem, how can a normal business get redundant Internet connections? The simplest, and at best half solution, is a router with two WAN connections and NATing out each port.
Now imagine you are using a laptop which is connected to a network with dual NATed WAN connections and you are in the middle of a Skype call. The connection associated with the Skype call will use one of the two WAN network ports and since NAT is used, the source address of the connection will be the IP address associated with the chosen WAN port. As we discussed before, this ‘binds’ the connection to the given WAN connection.
In our previous example of a phone switching to its cellular connection when the Wi-Fi connection drops, Skype was able to quickly decide to try to open another connection. This was possible because when the Wi-Fi connection dropped, Skype got a notification that its connection(s) were terminated.
In the case of a device, like our laptop, which is behind the gateway there is no such notification because no network interface attached to the local device failed. All Skype knows is that it has stopped receiving data – it has no idea why. This could be a transient error or perhaps the whole Internet died. This forces applications to rely on keep alive messages to determine when the network has failed. When a failure determination occurs, the application can try to open another connection. In the case of our dual NATed WAN connected network this new connection will succeed because the new connection will be NATed out the second WAN interface.
In the mean time, the user experienced an outage even though the network did still have an active connection to the Internet. The duration of this outage depends on how aggressive the application timeouts are. It can have short timeouts and risk flapping between connections or longer timeouts and provide a poorer experience. Of course this also assumes that the application includes this non-trivial functionality, most don’t.
Isn’t delivering packets the network’s job not the application’s?
Part 1: Internet Redundancy, Or Not
Previously I wrote about how true redundancy for Internet connections is only available to Internet providers and very large enterprises. This post continues from there.
I would guess that the fact that it’s not possible to get redundant Internet access is a big surprise to people who haven’t look into it in detail. Surprisingly though, if you have a smart phone or a laptop that you plugin to an Ethernet port, you live through the problems caused by this Internet protocol design flaw every day. These problems seem so normal that you may have never considered that reality could be otherwise.
Let’s start with the example of a laptop attached to a docking station at your desk. It’s very common to use the wired Internet connection at your desk vs. wireless because it typically offers faster, more consistent service. Consider the case of needing to transfer a large file while working at your desk. You start the transfer, it’s humming along in the background, and you switch over to another task. A few minutes later you remember that you have a meeting so you yank the laptop from its docking station and walk to the meeting room.
What just happened to the file transfer? The answer of course is that the file transfer died and you may be thinking, “Of course it died. The laptop lost its connection”. This seems normal because we’re all used to this brokenness.
Think back to the previous blog post. We were trying to get redundant Internet links to a small business and households and found that it’s not possible with the Internet protocols as they exist today. Now think about what the laptop is – it’s a computing system with two Internet connections. This really isn’t very different from a network with two connections. Ultimately, the reason the file transfer died is because of all the same limitations discussed in the last post related to network redundancy. That is, solving the problem of enabling multiple redundant connections for a network, solves the problem for individual hosts as well.
Now consider a smart phone user that starts a Skype voice or video conversation while in the office and then heads to the car to go meet a client. If you’ve accidentally tried this before you know that as you leave the range of the office Wi-Fi, the connection drops. In the particular case of Skype, it may be able to rejoin the conversation after the phone switches to the cellular data connection but most applications don’t even make an attempt at this. Like the laptop, a smart phone is just a computing device with multiple Internet connections.
One last example, your office server that runs Active Directory or performs some other important function. You probably would like network redundancy for this as well right? This also isn’t possible without low level ‘hacks’ like bonding two Ethernet ports to the same switch together.
Not only does the Internet not allow for true redundancy for networks, the lack of this functionality causes trouble for end hosts as well.
Imagine you are a business that wants to have redundant connections to the Internet. Given the importance of an active Internet connection for many businesses this is a reasonable thing for an IT shop or business owner to ask for. One could also consider the serious home gamer who can’t risk being cut off as another use case.
Let’s dig into the technical options for achieving Internet redundancy.
The first and most obvious path would be to purchase a router that has two WAN ports and ordering Internet service from two different providers. Bam, you are ready to go right? Well… not really.
The way this typically works is that the router will choose one of the two Internet connections for a given outbound connection. The policy could be always use connection A until it fails or be more dynamic and take some advantage of both connections at the same time. The problem with this approach is that because the traffic will be NATed towards each Internet provider, there is no way to fail a given connection from one Internet provider to another. So the failure of one of the Internet connections means that your voice call, SQL or game connection will die, probably after some annoyingly lengthy TCP or application level timeout expires. If the site is strictly doing short outbound connections such as the case with HTTP 1.1 traffic this isn’t such a big deal.
So the ‘get two standard Internet connections and a dual port WAN router’ approach sort of works. Let’s call it partially redundant.
How do we get to true redundancy that can survive a connection failure without dropping connections? To this we need the site’s network to be reachable through multiple paths. The standard way to do this is to obtain IP address space from one of the service providers or get provider independent IP space from one of the registries (such as ARIN). Given that IPv4 addresses are in short supply this isn’t a trivial task. The conditions that have to be met to get address space are well out of the reach of small and medium businesses. Even when the barriers can be met, it’s still archaic to have to do a bunch of paper work with a third party for something that is so obviously needed.
The real kicker is that the lack of IP space is only part of the problem. IPv6’s huge 128-bit address space doesn’t really help at all because to use both paths, the site or home’s IP prefix needs to exist in the global routing table. That is, every core router on the Internet needs an entry that tells it how to reach this newly announced chunk of address space. The specialized memory (CAM) used by these routers isn’t cheap so there is a strong incentive within the Internet operations community to keep this kind of redundancy out of the reach of everyone except other ISPs and large businesses.
So the simple option doesn’t really solve the problem and ‘true’ redundancy isn’t possible for most businesses. What about something over the top?
Consider a router that is connected to multiple standard Internet connections. It could maintain two tunnels, one over each connection, towards another router somewhere else on the Internet. To the rest of the Internet, this second router is where the business is connected to the Internet. If one of the site’s Internet connections fails, the routers can simply continue passing packets over the remaining live tunnel thereby maintaining connectivity to the end site. From an end user’s perspective, this solution mostly works but let’s think about the downsides. We’ve essentially made our site’s redundancy dependent on the tunnel termination router and its Internet connectivity whereas without this we are just at the mercy of the ISP’s network. Also, unless the end site obtains its own address space, this approach has all downsides of the first approach except the NAT related problems occur at the tunnel termination router instead of being on-site. Finally, if the site can get its own address space, why do the tunnel approach at all?
I should note, because someone will point it out in the comments, that for very large organizations it’s possible to get layer two connectivity to each site and essentially build their own internal internet. If they have enough public IP space they can achieve redundancy to the end site for connections with hosts on the public Internet. With private IP space, they can achieve redundancy for connections within their own network. Without public IP space, even these networks suffer from the NAT related failure modes.
To summarize, if you aren’t a very large business, there is no way to get true Internet connection redundancy with the current Internet protocols. That’s kinda sad.
Linux 3.13 was just released. As always there are lots of interesting new features but two stand out to me: nftables and cls_bpf.
Nftables is the replacement for iptables. It offers a new syntax, looks easier to use and has a simpler kernel implementation through the use of a JITed BFP-like language instead of dedicated field matching code.
Cls_bpf is a new traffic classifier that makes use of BPF to match packets for traffic shaping purposes. This is made possible by the BPF JIT that was added to the kernel some time ago.
Additionally, the BPF JIT can now also be used as a security mechanism to filter which syscalls a given process can use.
The commonality to all of these is a small, simple, fast and flexible component in the kernel with the more complex details located in userspace – I really like this design pattern.
Nftables, the new firewall infrastructure designed to replace iptables in the Linux kernel has just been merged. If you are a Linux kernel packet geek this is pretty exciting stuff. Unlike iptables, which has kernel code to parse and classify all kinds of different traffic types, nftables relies on a small BPF like bytecode language. The userspace tools simply generate the bytecode and pass it to the kernel for execution allowing new protocols to be supported without kernel changes. This will eventually replace a lot of complex code in the kernel and has a conceptually beauty that I really like.
Below are a few links for those interested: