This is a good article on TCP_NODELAY. The associated HN thread also has some interesting comments.
For another discussion of this topic, see the recent Oxide and Friends episode, also available in podcast form.
This is a good article on TCP_NODELAY. The associated HN thread also has some interesting comments.
For another discussion of this topic, see the recent Oxide and Friends episode, also available in podcast form.
The AT Protocol that powers BlueSky (distributed Twitter) is interesting.
https://steveklabnik.com/writing/how-does-bluesky-work
Especially the ability to use domain names as identifiers and the ability to move between servers while maintaining that identifier.
https://bsky.app/profile/coverfire.com
I’m not sure I have need for micro-blogging any more but perhaps a non-centralized version could be better.
We just published a new Podcast episode featuring David “Tubes” Tuber and Carlos Rodrigues from Cloudflare. We talked about Cloudflare’s speedtest and more generally, Internet experience.

This is worth reading.
https://tailscale.com/blog/quic-udp-throughput/
A few interesting things:
Once upon a time, much of the high-value and high-volume traffic on the Internet was TCP-based. Games and other real-time applications adopted UDP early to avoid the head-of-the-line blocking problems inherent in TCP’s design. However, these applications tend to use a relatively low traffic volume.
What’s changed?
A few things (at least):
As an example, below are the bitrates for TCP and UDP capture on my home router. This capture has all the traffic associated with the 50+ Internet-connected things in my house as well as:
Blue is UDP, red is TCP.
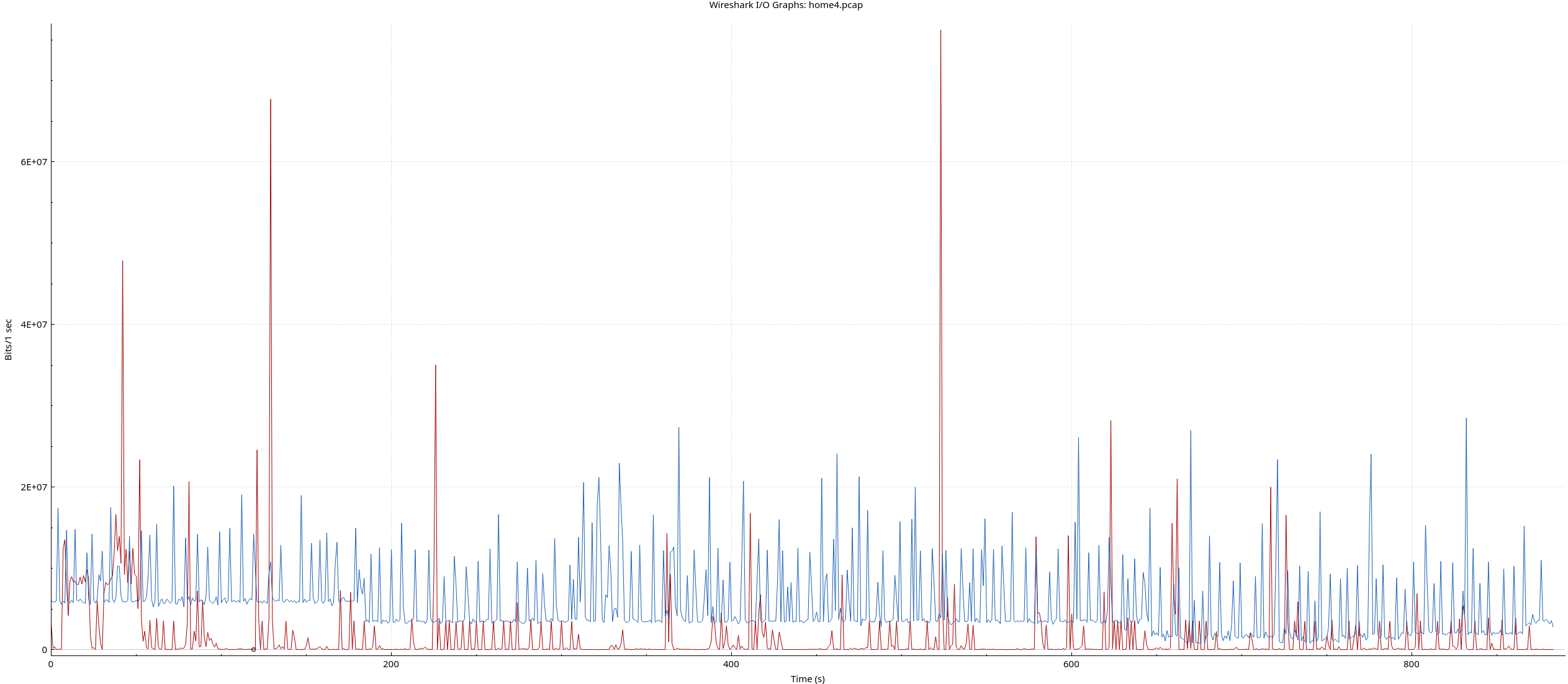
I suspect some people will find this surprising. UDP completely dominates this typical workload. Notice the long periods of near TCP-silence
Why? YouTube uses QUIC/UDP for content delivery. Google Meet uses UDP for video and audio. It’s likely the kid’s game is hidden in the large amount of UDP traffic as well. The little red spikes are likely web browsing activity.
Note that other video conferencing applications like Zoom also use UDP.
That’s bitrate; let’s look at the packet count.
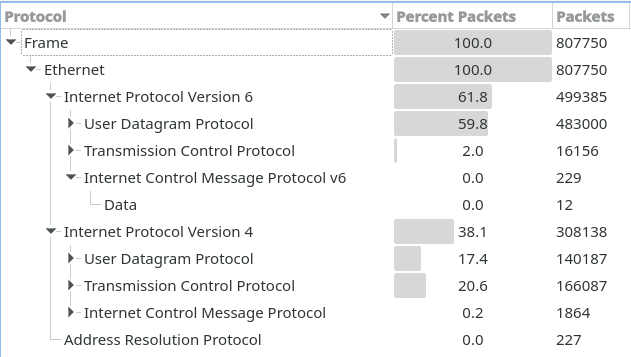
79% of packets are UDP. This isn’t your parent’s TCP-based Internet anymore.
QUIC is a newish transport protocol that is based on top of UDP. It offers the same reliable delivery model of TCP and more. A simple way to think of a QUIC connection is as a bunch of TCP flows riding on top of the same UDP flow.
Describing all the goodness in QUIC is outside the scope of this article. A few interesting pieces include:
To dig deeper, follow the rabbit trail from the Wikipedia QUIC page – https://en.wikipedia.org/wiki/QUIC. That page includes links to QUIC implementations in many languages.
Today QUIC is used extensively by Google. YouTube, Gmail, Search, and most other Google traffic use QUIC if you have a reasonably new browser.
But that’s far from all:
Finding more examples isn’t hard.
Given the many advantages of QUIC over TCP, we’ll likely see its usage continue to grow in all types of applications, from video conferencing to games and APIs.
Since its inception, HTTP, the protocol that underlies the web has been TCP based.
This is changing.
HTTP/3, the newest HTTP standard, is entirely based on QUIC to bring the benefits of QUIC to websites and applications.
Major CDN providers and HTTP libraries now already have full support for QUIC or are making progress. Cloudflare, for example, has extensive support (https://cloudflare-quic.com/).
It’s a brave new UDP world.