Linux Journal has an article in the January 2005 issue that introduces a doubly linked list that is designed for memory efficiency.
Typically elements in doubly linked list implementations consist of a pointer to the data, a pointer to the next node and a pointer to the previous node in the list.

The more memory efficient implementation described in the article stores a single offset instead of the next and previous pointers.
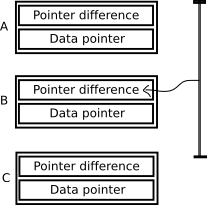
The pointer difference is calculated by taking the exclusive or (XOR) of the memory location of the previous and the next nodes. Like most linked list implementations a NULL pointer indicates a non-existent node. This is used at the beginning and end of the list. For the diagram above, the pointer differences would be calculated as follows:
A[Pointer difference] = NULL XOR B
B[Pointer difference] = A XOR C
C[Pointer difference] = B XOR NULL
One nice property of XOR is that it doesn’t matter what order the operation is applied. For example:
A XOR B = C
C XOR B = A
A XOR C = B
The memory efficient linked list uses this property of XOR for traversals. The trick is that any traversal operation requires both the address of current node and the address of either the preceding or following node.
Using the example figure above, calculating the address of the B node from A looks like:
B = NULL XOR A[Pointer difference]
What is really interesting is that traversing the list operates exactly the same in both directions. As shown below calculating the address of node A or C from B is simply depends on which direction the traversal is going.
A = C XOR B[Pointer difference]
C = A XOR B[Pointer difference]
The original article presents some time and space complexity results. I won’t bother repeating them here.
Very good! Sir(Mr. Dan Siemon)for your diagrammatic explanation to the article published in the linux journal on Jan 2005.
Really, by going through your clear explanation, it’s very much easy to understand.
Your explanation is great. By looking at the code in Linux Journal + ur diagramatic representation makes this
concept clearer.
kudos.
i read your article as well your journal but i’m still not as yet clear on the topic…well how the traversal takes place…if you coud elaborate mopre on how the ptr difference is calculated
I was thinking along the same lines, only considering pointer difference through subtraction and addition. This was naive, I was running into problems and XOR solves some of it.
I have a couple of questions about this implementation:
1. Since linked list memory is allocated from the free store, how will paging operations affect this? What if the pointer access is to a page that has been swapped out?
2. Does this assume flat memory addressing? What if the memory is segmented?
Thanks,
–KK
Paging operations shouldn’t affect the user process in any way. Modern operating systems completely hide virtual memory and paging from the process.
I haven’t worked with memory segments in a long, long time so I don’t have an answer for your second question without doing a bit of research. If you figure it out feel free to post the answer.
Pingback: The magic of XOR (Exclusive or) « Jules Dourlens
One thing which i think i understood frm ur article is:(please correct me if i m wrong!)
For example we r making a doubly link list of three nodes A,B,C
as
A B C
next –> next –>
<–prev <– prev
Now take XOR of A and B
as A XOR B=resultant address
store C in the resultant address
now the property of XOR u mentioned will be applicable
but we also need to perform the above thing which i mentioned
what is the time complexity for Xor linked list??