For an interesting opinion on software patents check this article out. I really like his conception of the line between what is patentable and what is not.
Software patents
Leave a reply
For an interesting opinion on software patents check this article out. I really like his conception of the line between what is patentable and what is not.
Linux Journal has an article in the January 2005 issue that introduces a doubly linked list that is designed for memory efficiency.
Typically elements in doubly linked list implementations consist of a pointer to the data, a pointer to the next node and a pointer to the previous node in the list.

The more memory efficient implementation described in the article stores a single offset instead of the next and previous pointers.
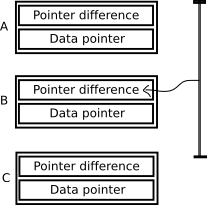
The pointer difference is calculated by taking the exclusive or (XOR) of the memory location of the previous and the next nodes. Like most linked list implementations a NULL pointer indicates a non-existent node. This is used at the beginning and end of the list. For the diagram above, the pointer differences would be calculated as follows:
A[Pointer difference] = NULL XOR B
B[Pointer difference] = A XOR C
C[Pointer difference] = B XOR NULL
One nice property of XOR is that it doesn’t matter what order the operation is applied. For example:
A XOR B = C
C XOR B = A
A XOR C = B
The memory efficient linked list uses this property of XOR for traversals. The trick is that any traversal operation requires both the address of current node and the address of either the preceding or following node.
Using the example figure above, calculating the address of the B node from A looks like:
B = NULL XOR A[Pointer difference]
What is really interesting is that traversing the list operates exactly the same in both directions. As shown below calculating the address of node A or C from B is simply depends on which direction the traversal is going.
A = C XOR B[Pointer difference]
C = A XOR B[Pointer difference]
The original article presents some time and space complexity results. I won’t bother repeating them here.
I am finally getting caught up on some magazine reading that I fell behind on during the school year. Today, I was reading a article called Parallel Universes by Max Tegmark in the May 2003 issue of Scientific American. I am not a physicist so some of this article is over my head but most of it was quite understandable. Reading that there are plausible arguments as to why parallel universes might exist was quite a surprise.
I found a couple of choice quotes that I think are worth sharing:
“But an entire ensemble is often much simpler than one of it’s members. This principle can be stated more formally using the notion of algorithmic information content. The algorithmic information content in a number is, roughly speaking, the length of the shortest computer program that will produce that number as output. For example, consider the set of all integers. Which is simpler, the whole set or just one number? Naively, you might think that a single number is simpler, but the entire set can be generated by quite a trivial computer program, whereas a single number can be hugely long. Therefore, the whole set is actually simpler.”
“The lesson is that complexity increases when we restrict out attention to one particular element in an ensemble, thereby losing the symmetry and simplicity that were inherent in the totality of all the elements taken together.”
These quotes jumped out at me because they touch on what I think is perhaps the most basic aspect of Computer Science and programming, finding the hidden simplicity. Often, there is a gorgeous, simple solution to the problem. It just takes time to get the complexity out of the way.
SlashDot recently posted an article about LOAF. LOAF is an interesting idea. The site is worth looking at for it’s own sake. However, what I found really interesting was the tidbit of computer science behind LOAF called a Bloom Filter.
A Bloom Filter uses multiple hash functions and a large bit array to represent a set. The set cannot be reconstructed from the Bloom Filter. There is a small possibility that the Bloom Filter will return a false positive but a false negative is impossible.
Here are some links with more information:
The original article on Bloom filters:
Communications of the ACM
Volume 13 , Issue 7 (July 1970)
Pages: 422 – 426
Year of Publication: 1970
ISSN:0001-0782
This article is available in the ACM digital library.
It looks like I have pretty much got my fourth year Computer Science courses figured out.
CS325: Law in Computer Science
An examination of aspects of law and policy that relate to the creation, protection and implementation of software and hardware; attention is directed towards issues of current importance of which every computer scientist should be aware.
CS402: Distributed and Parallel Systems
Issues arising in distributed and parallel systems and applications; related architectures such as connection machines, shared memory multiprocessors.
CS413: Cryptography and Security
Survey of the principles and practise of cryptography and network security: classical cryptography, public-key cryptography and cryptographic protocols, network and system security.
CS444: Semantics of Programming Languages
Operational, denotational, and axiomatic semantics; lambda-calculus.
CS445: Analysis of Algorithms II
Parallel, distributed, probabilistic, and geometric algorithms; design and analysis; computational geometry; fractals and graphtals.
CS447: Compiler Theory
Syntax-directed translation; LR(k), LL(k), attribute grammars; code generation; optimization; compiler compilers; code generator generators.
CS457: Computer Networks II
Network layering, performance, management, modelling and simulation; faults and failures.
CS490: Thesis
A project or research paper completed with minimal faculty supervision. An oral presentation plus a written submission will be required.
It was pretty hard to decide which courses to take this year. The first big decision was to take the courses necessary for the Four-year BSc Honours Computer Science degree instead of the Four-year Bsc Honours Computer Science with Software Engineering Specialization degree. Although the Software Engineering sounds a little more impressive it seems to me to be the easy way out. The courses required for the Software Engineering specialization look easier and less interesting to me. Worse, I would not be able to take many of the more theoretical courses I listed above.
After making the above decision I still had to decide between
CS338A: Computer Graphics I
Graphics primitives. The viewing pipeline; clipping and visibility problems. The graphical kernel system; picture generation and user interfaces.
and
CS444: Semantics of Programming Languages
Operational, denotational, and axiomatic semantics; lambda-calculus.
It was a choice between specializing more in programming languages or broadening my knowledge with the Computer Graphics course. This was a tough decision because I know very little about graphics and would like to know more. I chose CS444.
The second course decision was between
CS325: Law in Computer Science
An examination of aspects of law and policy that relate to the creation, protection and implementation of software and hardware; attention is directed towards issues of current importance of which every computer scientist should be aware.
and
CS413: Foundations of Computer Science II
Formal languages; recursive functions; abstract complexity; automaton models; array machines; systolic systems; cellular automata.
I decided on CS325 for a couple of reasons. First, I have become very interested in intellectual properly issues. Second, I don’t want the spring term to be too hard because a lot of time will be consumed by my thesis.
I do feel like I should be taking another mathematics course or two but there just isn’t room.
It should be a very interesting year. I wish it were possible to take every course in the Computer Science department. Also, I still have to decide which option credit to take. I’m thinking economics.
Now, I just need to decide whether or not I will do a masters next year.